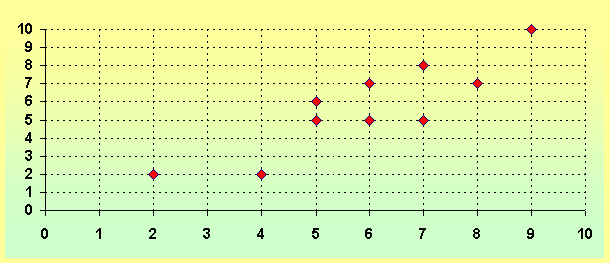
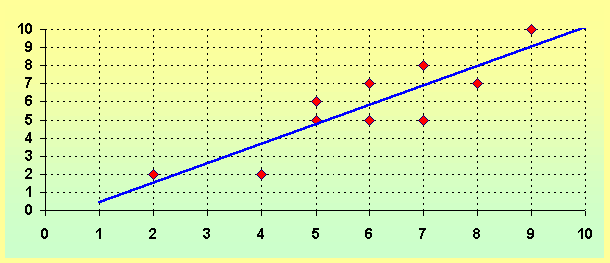
EJEMPLO 1

El Teorema Central del Límite dice que si tenemos un grupo numeroso de variables independientes y todas ellas siguen el mismo modelo de distribución (cualquiera que éste sea), la suma de ellas se distribuye según una distribución normal.
EJEMPLO: la variable "tirar una moneda al aire" sigue la distribución de Bernouilli. Si lanzamos la moneda al aire 50 veces, la suma de estas 50 variables (cada una independiente entre si) se distribuye según una distribución normal.
Este teorema se aplica tanto a suma de variables discretas como de variables continuas.
Los parámetros de la distribución normal son:
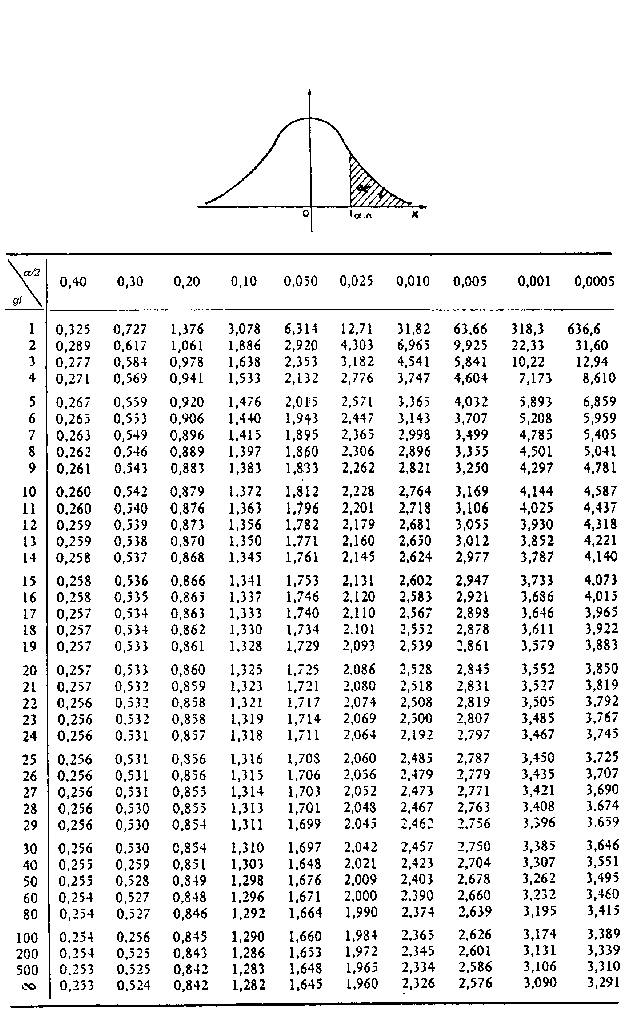
EJEMPLO: queremos conocer la probabilidad acumulada en el valor 2,75.Entonces buscamos en la columna de la izquierda el valor 2,7 y en la primera fila el valor 0,05. La casilla en la que se interseccionan es su probabilidad acumulada (0,99702, es decir 99.7%).
Es el modelo de distribución más utilizado en la práctica, ya que multitud de fenómenos se comportan según una distribución normal.
Esta distribución de caracteriza porque los valores se distribuyen formando una campana de Gauss, en torno a un valor central que coincide con el valor medio de la distribución:
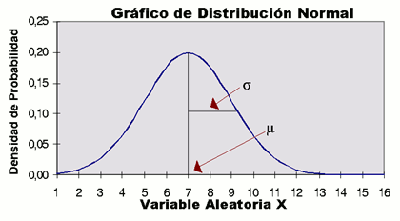
Un 50% de los valores están a la dercha de este valor central y otro 50% a la izquierda
Esta distribución viene definida por dos parámetros:
X: N (m, s 2)
m : es el valor medio de la distribución y es precisamente donde se sitúa el centro de la curva (de la campana de Gauss).
s 2 : es la varianza. Indica si los valores están más o menos alejados del valor central: si la varianza es baja los valores están próximos a la media; si es alta, entonces los valores están muy dispersos.
Cuando la media de la distribución es 0 y la varianza es 1se denomina "normal tipificada", y su ventaja reside en que hay tablas donde se recoge la probabilidad acumulada para cada punto de la curva de esta distribución.
Además, toda distribución normal se puede transformar en una normal tipificada:
EJEMPLO: una variable aleatoria sigue el modelo de una distribución normal con media 10 y varianza 4. Transformarla en una normal tipificada.
X: N (10, 4)
Para transformarla en una normal tipificada se crea una nueva variable (Y) que será igual a la anterior (X) menos su media y dividida por su desviación típica (que es la raíz cuadrada de la varianza)

Esta nueva variable se distribuye como una normal tipificada, permitiéndonos, por tanto, conocer la probabilidad acumulada en cada valor.
La distribución uniforme es aquella que puede tomar cualquier valor dentro de un intervalo, todos ellos con la misma probabilidad.
Es una distribución continua porque puede tomar cualquier valor y no únicamente un número determinado (como ocurre en las distribuciones discretas).
EJEMPLO: el precio medio del litro de gasolina durante el próximo año se estima que puede oscilar entre 140 y 160 ptas. Podría ser, por tanto, de 143 ptas., o de 143,4 ptas., o de 143,45 ptas., o de 143,455 ptas, etc. Hay infinitas posibilidades, todas ellas con la misma probabilidad.
Su función de densidad, aquella que nos permite conocer la probabilidad que tiene cada punto del intervalo, viene definida por:

Donde:
b: es el extremo superior (en el ejemplo, 160 ptas.)
a: es el extremo inferior (en el ejemplo, 140 ptas.)
La distribución multihipergeométrica es similar a la distribución hipergeométrica, con la diferencia de que en la urna, en lugar de haber únicamente bolas de dos colores, hay bolas de diferentes colores.
EJEMPLO: en una urna hay 7 bolas blancas, 3 verdes y 4 amarillas: ¿cuál es la probabilidad de que al extraer 3 bolas sea cada una de un color distinto?
La distribución multihipergeométrica sigue el siguiente modelo:

Donde:
X1 = x1: indica que el suceso X1 aparezca x1 veces (en el ejemplo, que una de las bolas sea blanca)
N1: indica el número de bolas blancas que hay en la urna (en el ejemplo, 7 bolas)
N: es el número total de bolas en la urna (en el ejemplo, 14 bolas)
n: es el número total de bolas que se extraen (en el ejemplo, 3 bolas)

Luego:
P = 0,2307
Es decir, que la probabilidad de sacar una bola de cada color es del 23,07%.
La distribución multinomial es similar a la distribución binomial, con la diferencia de que en lugar de dos posibles resultados en cada ensayo, puede haber múltiples resultados:
La distribución multinomial sigue el siguiente modelo:
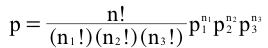
Donde:
X1 = x1: indica que el suceso X1 aparezca x1 veces (en el ejemplo, que el partido POPO lo hayan votado 3 personas)
n: indica el número de veces que se ha repetido el suceso (en el ejemplo, 5 veces)
n!: es factorial de n (en el ejemplo: 5 * 4 * 3 * 2 * 1)
p1: es la probabilidad del suceso X1 (en el ejemplo, el 40%)
Las distribución hipergeométrica es el modelo que se aplica en experimentos del siguiente tipo:
En una urna hay bolas de dos colores (blancas y negras), ¿cuál es la probabilidad de que al sacar 2 bolas las dos sean blancas?
Son experimentos donde, al igual que en la distribución binomial, en cada ensayo hay tan sólo dos posibles resultados: o sale blanca o no sale. Pero se diferencia de la distribución binomial en que los distintos ensayos son dependientes entre sí:
Si en una urna con 5 bolas blancas y 3 negras en un primer ensayo saco una bola blanca, en el segundo ensayo hay una bola blanca menos por lo que las probabilidades son diferentes (hay dependencia entre los distintos ensayos).
La distribución hipergeométrica sigue el siguiente modelo:

EN DONDE:

Vamos a tratar de explicarlo:
N: es el número total de bolas en la urna
N1: es el número total de bolas blancas
N2: es el número total de bolas negras
k: es el número de bolas blancas cuya probabilidad se está calculando
n: es el número de ensayos que se realiza

El número "e" es 2,71828
" l " = n * p (es decir, el número de veces " n " que se realiza el experimento multiplicado por la probabilidad " p " de éxito en cada ensayo)
" k " es el número de éxito cuya probabilidad se está calculando
Las distribución binomial parte de la distribución de Bernouilli:
La distribución de Bernouiili se aplica cuando se realiza una sola vez un experimento que tiene únicamente dos posibles resultados (éxito o fracaso), por lo que la variable sólo puede tomar dos valores: el 1 y el 0
La distribución binomial se aplica cuando se realizan un número"n" de veces el experimento de Bernouiili, siendo cada ensayo independiente del anterior. La variable puede tomar valores entre:
0: si todos los experimentos han sido fracaso
n: si todos los experimentos han sido éxitos
EJEMPLO: se tira una moneda 10 veces: ¿cuantas caras salen? Si no ha salido ninguna la variable toma el valor 0; si han salido dos caras la variable toma el valor 2; si todas han sido cara la variable toma el valor 10
La distribución de probabilidad de este tipo de distribución sigue el siguiente modelo:

Ampliemos un poco más el tema...
EJEMPLO: Probabilidad de salir cara al lanzar una moneda al aire (sale cara o no sale); probabilidad de ser admitido en una universidad (o te admiten o no te admiten); probabilidad de acertar una quiniela (o aciertas o no aciertas)
Al haber únicamente dos soluciones se trata de sucesos complementarios:
A la probabilidad de éxito se le denomina "p"
A la probabilidad de fracaso se le denomina "q"
Verificándose que:
p + q = 1
EJEMPLO: si se lanza una moneda al aire puede salir cara o cruz; si se tira un dado puede salir un número de 1 al 6; en una ruleta el número puede tomar un valor del 1 al 32.
EJEMPLO: el peso medio de los alumnos de una clase puede tomar infinitos valores dentro de cierto intervalo (42,37 kg, 42,3764 kg, 42, 376541kg, etc); la esperanza media de vida de una población (72,5 años, 7,513 años, 72, 51234 años).

EJEMPLO: supongamos que si llueve la probabilidad de que ocurra un accidentes es x% y si hace buen tiempo dicha probabilidad es y%. Este teorema nos permite deducir cuál es la probabilidad de que ocurra un accidente si conocemos la probabilidad de que llueva y la probabilidad de que haga buen tiempo.La fórmula para calcular esta probabilidad es:

La probabilidad compuesta (o regla de multiplicación de probabilidades) se deriva de la probabilidad condicionada:
La probabilidad de que se den simultáneamente dos sucesos (suceso intersección de A y B) es igual a la probabilidad a priori del suceso A multiplicada por la probabilidad del suceso B condicionada al cumplimiento del suceso A.
Las probabilidades condicionadas se calculan una vez que se ha incorporado información adicional a la situación de partida.
Las probabilidades condicionadas se calculan aplicando la siguiente fórmula:

Donde:

Ejemplo: C10,4 son las combinaciones de 10 elementos agrupándolos en subgrupos de 4 elementos: Es decir, podríamos formar 210 subgrupos diferentes de 4 elementos, a partir de los 10 elementos.

Ejemplo: V10,4 son las variaciones de 10 elementos agrupándolos en subgrupos de 4 elementos: Es decir, podríamos formar 5.040 subgrupos diferentes de 4 elementos, a partir de los 10 elementos.

Ejemplo: P10 son las permutaciones de 10 elementos: Es decir, tendríamos 3.628.800 formas diferentes de agrupar 10 elementos.
Para aplicar la Regla de Laplace el cálculo de los sucesos favorables y de los sucesos posibles a veces no plantea ningún problema, ya que son un número reducido y se pueden calcular con facilidad.
Sin embargo, a veces calcular el número de casos favorables y casos posibles es complejo y hay que aplicar reglas matemáticas:
Las reglas matemáticas que nos pueden ayudar son el cálculo de combinaciones, el cálculo devariaciones y el cálculo de permutaciones.
COMBINACIONES: Determina el número de subgrupos de 1, 2, 3, etc. elementos que se pueden formar con los "n" elementos de una nuestra. Cada subgrupo se diferencia del resto en los elementos que lo componen, sin que influya el orden.
EJEMPLO, calcular las posibles combinaciones de 2 elementos que se pueden formar con los números 1, 2 y 3. Se pueden establecer 3 parejas diferentes: (1,2), (1,3) y (2,3). En el cálculo de combinaciones las parejas (1,2) y (2,1) se consideran idénticas, por lo que sólo se cuentan una vez.
VARIACIONES: Calcula el número de subgrupos de 1, 2, 3, etc.elementos que se pueden establecer con los "n" elementos de una muestra. Cada subgrupo se diferencia del resto en los elementos que lo componen o en el orden de dichos elementos (es lo que le diferencia de las combinaciones).
EJEMPLO, calcular las posibles variaciones de 2 elementos que se pueden establecer con los número 1, 2 y 3. Ahora tendríamos 6 posibles parejas: (1,2), (1,3), (2,1), (2,3), (3,1) y (3,3). En este caso los subgrupos (1,2) y (2,1) se consideran distintos.
PERMUTACIONES: Cálcula las posibles agrupaciones que se pueden establecer con todos los elementos de un grupo, por lo tanto, lo que diferencia a cada subgrupo del resto es el orden de los elementos.
EJEMPLO, calcular las posibles formas en que se pueden ordenar los número 1, 2 y 3. Hay 6 posibles agrupaciones: (1, 2, 3), (1, 3, 2), (2, 1, 3), (2, 3, 1), (3, 1, 2) y (3, 2, 1).
Entre los sucesos compuestos se pueden establecer distintas relaciones:
La probabilidad mide la frecuencia con la que aparece un resultado determinado cuando se realiza un experimento.
El experimento tiene que ser aleatorio, es decir, que pueden presentarse diversos resultados, dentro de un conjunto posible de soluciones, y esto aún realizando el experimento en las mismas condiciones. Por lo tanto, a priori no se conoce cual de los resultados se va a presentar:
Hay experimentos que no son aleatorios y por lo tanto no se les puede aplicar las reglas de la probabilidad.
Antes de calcular las probabilidades de un experimento aleaotorio hay que definir una serie de conceptos: